This is Part 3. There is also Part 1, Part 2, Part 4, Part 5, Part 6, Part 7 and Part 8.
This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script.
Name: CLIP Guided Diffusion v4
Author: Katherine Crowson
Original script: https://colab.research.google.com/drive/1V66mUeJbXrTuQITvJunvnWVn96FEbSI3
Time for 512×512 on a 3090: 3 minutes 05 seconds
Maximum resolution on a 24 GB 3090: Locked to 512×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Another CLIP Guided Diffusion script. Locked to 512×512 resolution. Like the other CLIP Diffusion scripts, some of the results can be very detailed and interesting, but a lot of time it is hit and miss to get a result that reliably matches the input phrase. When it gets a “hit” it can create very detailed impressive results, but the amount of “misses” stops it from getting a great rating. Still worth a try if you have the patience to run a large batch of images waiting for the best results. The following samples came hand picked from a large batch run of random prompt phrases.

a forest clearing

a storybook illustration of a nightmare

an impressionist painting of a cemetery

Harry Potter in the style of Rembrandt

a detailed painting of a witch

a babbling brook

a desert oasis

a hyperrealistic painting of an android
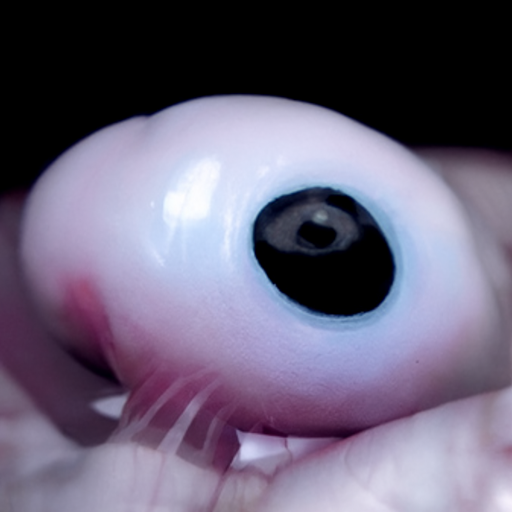
eyeballs

a cross stitch of Buzz Lightyear
Name: CLIP Guided Decision Transformer
Author: Katherine Crowson
Original script: https://colab.research.google.com/drive/1V66mUeJbXrTuQITvJunvnWVn96FEbSI3
Time for 512×512 on a 3090: 1 minutes 13 seconds
Maximum resolution on a 24 GB 3090: Locked to 384×384
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Another one from Katherine Crowson. Some of the results can be very detailed and interesting, but a lot of time it is hit and miss to get a result that reliably matches the input phrase. When it gets a “hit” it can create very detailed impressive results, but the amount of “misses” stops it from getting a great rating. The following samples came hand picked from a large batch run of random prompt phrases.
Another good point for CLIP Decsision Transformer is that it will generate a batch of images from each run. So rather than a single image for the prompt text you can specify (for example) 8 images to be generated from the prompt. This allows a much larger set of images to be quickly generated to find those great outputs in.
For these images I have enhanced the resolution 4x using Real-ESRGAN (the thumnails are the original output images and the clicked images are resized x4).

a detailed painting of a palace by Thomas Kinkade

a drawing of Chewbacca

a forest path

a renaissance painting of a mountain range

a rough seascape

a rough seascape

a spooky forest

an oil on canvas painting of a western town

Frankenstein

The Grand Canyon
Name: CLIPIT
Author: dribnet
Original script: https://github.com/dribnet/clipit
Time for 512×512 on a 3090: 2 minutes 38 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×480
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Another GAN+CLIP script. Gives nice results that tend to match the prompt text more closely. This one is heavy on VAM usage.

a happy family by Piet Mondiran

a landscape

a peacock

a tropical beach by Thomas Kinkade

a woodcut of Dracula

an ambient occlusion render of a zombie

eyeballs in the style of Claude Monet
Name: Art Machine
Author: Hillel Wayne
Original script: https://colab.research.google.com/drive/1n_xrgKDlGQcCF6O-eL3NOd_x4NSqAUjK
Time for 512×512 on a 3090: 4 minutes 04 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×480
Maximum resolution on an 8GB 2080: 256×256 1 minute 50 seconds
Description: Another VQGAN+CLIP scipt.

a charcoal drawing of a kitchen

a mosaic of a mountain path | CryEngine

a silk screen of a tropical beach in the style of Kandinsky

a woodcut of a nightmare creature

an illustration of of a mountainscape

an ultrafine detailed painting of a green tree frog as created by Craig Mullins

Dracula

Planets
Name: VQGAN+CLIP v5
Author: Max Woolf
Original script: https://colab.research.google.com/drive/1wkF67ThUz37T2_oPIuSwuO4e_-0vjaLs
Time for 512×512 on a 3090: 2 minutes 13 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×480
Maximum resolution on an 8GB 2080: 256×256 2 minutes 02 seconds
Description: Another VQGAN+CLIP scipt. More abstract results from this one.

a desert oasis in the style of Salvador Dali

a hyperrealistic painting of a dragon

Big Bird

Cthulhu

Robert DeNiro

Yoda “hmmm, abstract I am”
Name: Zoetrope 5.5
Author: Bearsharktopusdev
Original script: https://colab.research.google.com/drive/1LpEbICv1mmta7Qqic1IcRTsRsq7UKRHM
Time for 512×512 on a 3090: 3 minutes 27 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: 256×256 3 minutes 23 seconds
Description: Updated version of Zoetrope 5. Supports more VQGAN models, CLIP models and optimizers compared to Zoetrope 5.

a cephalopod

a flemish baroque of a demon

a photo of a submarine in the style of Vincent van Gogh

a snail

Cthulhu
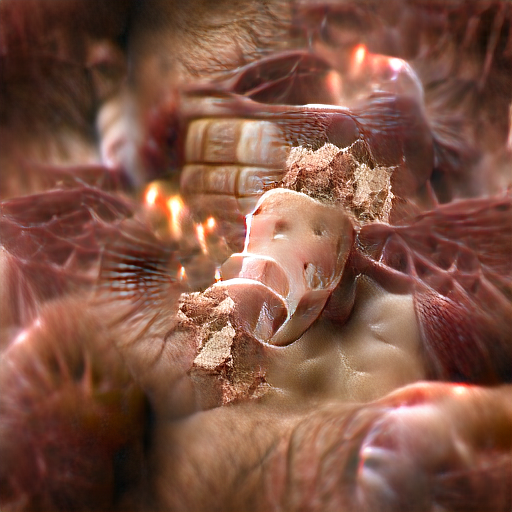
flesh
Name: Zeta Quantize
Author: afiaka87
Original script: https://colab.research.google.com/gist/afiaka87/a97cca3b54c02209b94ff805224f9eb5/zeta_quantize.ipynb
Time for 512×512 on a 3090: 4 minutes 18 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: 256×256 5 minutes 01 seconds
Description: Another VQGAN+CLIP scipt.

a cute creature made of silver

a detailed painting of a cephalopod

a detailed painting of a ghost

a forest fire made of copper

a peacock

a sketch of a Pokemon character in the style of Odilon Redon

a watercolor painting of dense woodland
Name: Experimental VQGAN
Author: Various
Original script: https://colab.research.google.com/drive/1jx3klUxlGbYUwvtqzC9SYl4XZKHL3R81
Time for 512×512 on a 3090: 1 minutes 12 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: 256×256 0 minutes 52 seconds
Description: Very nice smooth results from this one.

a desert oasis in the style of Craig Mullins

a dragon

a manga drawing of a happy alien

a nightmare

a surrealist painting of love

a watercolor painting of a lighthouse

an airbrush painting of a well kept garden by Piet Mondiran

Cookie Monster
Name: SlideShowVisions
Author: Active Galaxy
Original script: https://colab.research.google.com/drive/1IihC4ZJvCh_tOgBVd900BzHX-ulPEFsa
Time for 512×512 on a 3090: 2 minutes 25 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: 128×128 1 minute 56 seconds
Description: Tends to give more abstract paper cutout looks.

a happy child

a house vivid colors

a sea monster

a thunder storm

a tree

a woodcut of war

an engraving of zombies

Han Solo
Name: Quick CLIP Guided Diffusion
Author: Daniel Russell
Original script: https://colab.research.google.com/drive/1FuOobQOmDJuG7rGsMWfQa883A9r4HxEO
Time for 512×512 on a 3090: 43 seconds
Maximum resolution on a 24 GB 3090: 512×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Modified version of CLIP Guided Diffusion that gets results quicker. Option for 256×256 or 512×512 sized images. Still very hit and miss when getting images that resemble the input prompt. The following samples came from a large overnight batch run of random prompts.

a cathedral

a digital painting of a space nebula

a lounge room

a monkey | lens flare

a nightmare creature

a rough seascape

a landscape

an android

an attractive woman

an oil on canvas painting of a cloudy sunset
Name: CLIP Guided Diffusion v5
Author: Katherine Crowson
Original script: https://colab.research.google.com/drive/1QBsaDAZv8np29FPbvjffbE1eytoJcsgA
Time for 512×512 on a 3090: 3 minutes 48 seconds
Maximum resolution on a 24 GB 3090: Locked to 512×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Another CLIP Guided Diffusion script. Locked to 512×512 resolution. Needs less VRAM than the previous versions. The following samples came hand picked from a large batch run of random prompt phrases.

a cityscape

a gorilla

Cthulhu by Craig Mullins

computer rendering of Emporer Palpatine made of cheese by Evan Charlton

digital art of a mountainscape as created by Persis Goodale Thurston Taylor

a digital rendering of Chewbacca

an ugly person
See this tweet for an example of using CLIP Guided Diffusion to stylize a portrait.
Name: MSE Regulized Modified
Author: jbusted
Original script: https://colab.research.google.com/drive/1gFn9u3oPOgsNzJWEFmdK-N9h_y65b8fj
Time for 512×512 on a 3090: 3 minutes 02 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: 256×256 2 minutes 45 seconds
Description: Modified and updated version of the previous “MSE Regulized VQGAN+CLIP” script. Less likely to suffer the previous script’s issue of subjects floating in a purple void.

a bronze sculpture of a planet

a cave by Asher Brown Durand

a charcoal drawing of Emporer Palpatine

a cozy den
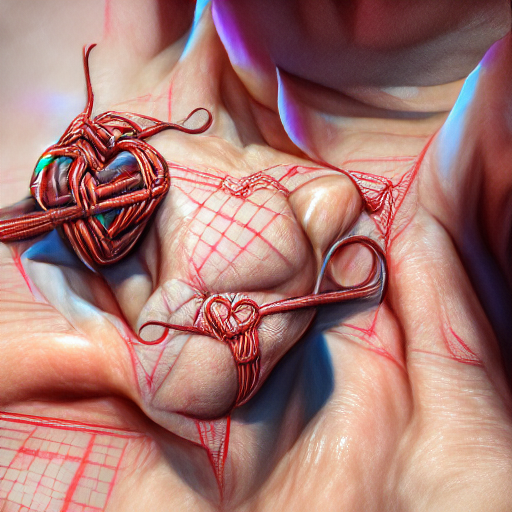
a detailed drawing of a heart made of string by William MacTaggart

a digital rendering of Arnold Schwarzenegger made of metal by Muriel Brandt

a lounge room

a palace by Jules Joseph Lefebvre

an oil on canvas painting of a lush rainforest

an oil on canvas painting of Cookie Monster
Name: Pixray
Author: dribnet
Original script: https://colab.research.google.com/github/dribnet/clipit/blob/master/demos/Start_Here.ipynb
Time for 512×512 on a 3090: 1 minutes 44 seconds
Maximum resolution on a 24 GB 3090: 768×768 or 1120×720
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Updated version of the previous “CLIPIT” script.

a bronze sculpture of a nightmare creature

a fire breathing dragon by Jan Baptist Weenix

a morning landscape

a surrealist sculpture of an elephant

a watercolor painting of an astronaut

an oil painting of a worried woman | Rendered in Cinema4D

an ugly creature

Dracula

Frankenstein

vector art of a forest clearing
Name: CLIP Guided Diffusion v6
Author: Dango233
Original script: https://colab.research.google.com/drive/14xBm1aSxQLbq26-jmDJi8I1HJ4ti5ybt
Time for 512×512 on a 3090: 3 minutes 10 seconds
Maximum resolution on a 24 GB 3090: Locked to 512×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Latest CLIP Guided Diffusion script. The best one yet. Capable of some very nice results.

a hyperrealistic painting of a human

a sketch of planets

a storybook illustration of a cloudy sunset

a wizard | vivid colors

an art deco sculpture of a planet

an attractive man by John Linnell

an oil on canvas painting of satan

an oil painting of a clown

digital art of an ugly person by Avigdor Arikha

princess in sanctuary trending on artstation photorealistic portrait of a young princess
Name: CLIPDraw
Author: Kevin Frans
Original script: https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb
Time for 512×512 on a 3090: 7 minutes 10 seconds
Maximum resolution on a 24 GB 3090: Huge. 4096×4096 and beyond.
Maximum resolution on an 8GB 2080: 1024×1024
Description: Generates images by a series of lines. Very abstract results.

a cloudy sunset

a digital painting of a rose

a sad clown

an abstract painting of Yoda

an etching of a library

The Sydney Harbour Bridge
Any Others I Missed?
Do you know of any other colabs and/or github Text-to-Image systems I have missed? Let me know and I will see if I can convert them to work with Visions of Chaos for a future release. If you know of any public Discords with other colabs being shared let me know too.
Jason.

Did you edit any of the default settings for the CLIP Guided Diffusion v6 notebook when generating any of the images? The default number of steps seems to be 124, do you know how to increase that value?
The CLIP Guided Diffusion v6 iterations can be confusing.
The iterations count (that gets automatically set) comes from the “Timestep respacing” values. These are totaled up. 30+50+70=150. That value loses 6 iterations internally as part of the way the script works, so you will only get 144 actual iterations.
I haven’t had to increase iterations for any of the samples or other images. Do you have an example of a prompt that looks like it could benefit from more iterations?
If you want to increase iterations, then add an amount to each of the respacing values. eg change 30,50,70 to 40,60,80 to get anew total of 180 iterations.
If you have a GPU with enough VRAM I recommend you use the “Multi-Perceptor CLIP Guided Diffusion” script instead. It has improvements over the v6 script and uses a single iterations setting. The results are superior in my opinion.
Jason.
Have you tried this update to Katherine’s CLIP Guided Diffusion 512×512 notebook: https://colab.research.google.com/drive/1mpkrhOjoyzPeSWy2r7T8EYRaU7amYOOi
Just curious about your thoughts and what you think are the “best” settings tweaks. This one seems to take ~13.5 minutes for 500 steps using a Tesla P100.
Yes I have tried that script. Scroll down to the last part here;
It is included in the latest version of Visions of Chaos.
Takes 2 minutes 28 seconds per image on a local 3090.
I use 5000 guidance scale, 50 TV scale, 50 range scale, 128 cutouts, 1 cutout batch. I also use ddim iterations as that seems to give slightly better results with that script.
Jason.